Anh em làm Blockchain dev chắc không lạ gì cảnh: Code chạy ngon lành cành đào cả năm trời, bỗng một ngày đẹp trời mạng lưới (chain) update, giảm block time (thời gian đóng block), tăng giới hạn Gas... và hệ thống backend của bắt đầu "kêu cứu".
Đó chính xác là những gì đã xảy ra với hệ thống **Bắn Noti** cho BNB Chain.
🛑 Vấn đề (The Crisis)
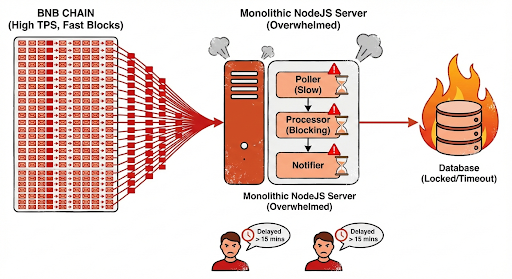
Hệ thống cũ của mình khá đơn giản:
- Poller: Cứ 3s gọi RPC check block mới.
- Processor: Lấy transaction -> Parse data -> Check điều kiện.
- Notifier: Bắn notify.
Mọi thứ vẫn ổn cho đến khi:
- BNB Chain giảm block time (nhanh hơn).
- Lượng transaction trong một block tăng vọt (TPS tăng).
Hậu quả:
- NodeJS Event Loop bị chặn (block) liên tục vì xử lý lượng data quá lớn.
- RPC Provider trả về lỗi `429 Too Many Requests` hoặc timeout.
- CPU/RAM 100% nhưng vẫn tải không kịp
- Database bị lock do write quá nhiều record nhỏ lẻ.
- User nhận noti trễ cả ngày hoặc mất tiêu luôn
🛠 Giải pháp Refactor (The Fix)
Không thể "lấy tiền đè người" bằng cách nâng server mãi được, team quyết định đập đi xây lại luồng xử lý (Architecture Refactor). Dưới đây là 5 mũi nhọn team mình đã triển khai:
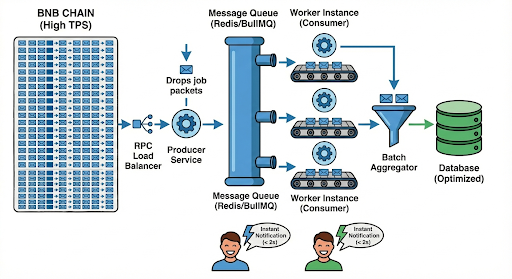
1. Chia để trị: Mô hình Producer - Consumer (Message Queue)
Trong hệ thông cũ, mọi tác vụ đều nằm trong 1 cục repo duy nhất, code đan xen và nhiều ràng buộc. Khi mình nhận phần code thì đã bắt đầu được thiết kế lại.
Thay vì xử lý tuần tự (crawl -> process -> notify), tôi tách ra:
- Producer: Chỉ làm một việc duy nhất là fetch block và đẩy raw transaction vào hàng đợi (Redis/SQS). Việc này cực nhanh. Để tiết kiệm băng thông và tránh limit message size mình có zip message lại trước khi gửi đi. Thời gian zip chắc nhắn nhanh hơn để gửi raw.
- Consumer (Worker): Nhiều worker chạy song song lấy job từ Queue ra xử lý.
👉 *Kết quả:* Việc crawl block không bao giờ bị chậm nhịp, dù việc xử lý logic có tốn thời gian bao nhiêu.
2. Batch Processing (Xử lý theo lô)
Thay vì Insert Database từng giao dịch (1 row/lần), ta gom (aggregator) lại:
- Kéo một lượng message đủ cho Consumer xử lý
- Ví dụ: Gom 100 giao dịch hoặc đợi 500ms -> Thực hiện `bulkInsert` một lần.
👉 *Kết quả:* Giảm tải IO cho Database.
3. RPC Load Balancer & Fallback
Khi TPS cao, RPC rất dễ tạch. Tôi không phụ thuộc vào 1 node nữa:
- Dùng một mảng các RPC Endpoint (cả free lẫn paid).
- Tự động switch node nếu node hiện tại bị timeout hoặc chậm.
4. Xử lý Idempotency (Chống trùng lặp)
Khi chạy nhiều Worker, rủi ro xử lý trùng một transaction là rất cao (đặc biệt khi mạng re-org).
- Dùng Redis để cache `txHash` đã xử lý với TTL (Time-to-live) ngắn hạn.
- Đảm bảo user không bao giờ nhận 2 cái noti cho cùng 1 giao dịch.
5. Cái nút cổ chai
- Trong qua trình refactor, sau nhiều lần chạy thử vào đo đạc metrics các kiểu cảm thấy chưa hài lòng với kết quả này, tụi mình đi sau hơn và nhận ra tác vụ chính trong code đang chiếm quá nhiều thời gian để chạy. Nó đang chạy tuần tự để kiểm tra lần lượt các case (kiểu như kiểm tra A → B → C ….. Z), `worst case` là phải lặp hết cả chục lần không cấn thiết.
- Phần code optimize này là điểm khó thấy nếu chỉ chăm chăm dựng cái hệ thống mà không đi sâu phân tích traces, metrics.
- Bắt đúng mạch, phần này mình tạo sẵn map functions cho từng case, trong `txInput` đã sẵn có thông tin, chỉ cần bóc nó ra duyệt trong map, bàn toán từ O(n) thành O(1)
📈 Kết quả sau thời gian Refactor
- Hệ thống chịu tải gấp nhiều lần lượng TPS cũ.
- Độ trễ notification giảm từ "vài phút" xuống còn **< vài giây**.
- CPU Server giảm nhiệt, anh em Dev ngủ ngon hơn.